Many introductions to Bayesian analysis use relatively simple didactic examples (e.g. making inference about the probability of success given bernoulli data). While this makes for a good introduction to Bayesian principles, the extension of these principles to regression is not straight-forward.
This post will sketch out how these principles extend to simple linear regression. Along the way, I will derive the posterior conditional distributions of the parameters of interest, present R code for implementing a Gibbs sampler, and present the so-called grid point method.
I’ve had trouble with R code snippets in wordpress before, so I will not present code in the post. Instead, I’ll host the code on GitHub. You can follow along with the code as you go through the post.
A Bayesian Model
Suppose we observe data 



Of interest is making inference about 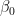

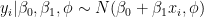

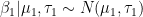

Assuming the hyperparameters 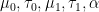
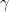
![p(\beta_0, \beta_1, \phi | \vec y) \propto \Big [\prod_{i=1}^n p(y_i | \beta_0, \beta_1, \phi )\Big] p( \beta_0 | \mu_0, \tau_0 ) p(\beta_1 | \mu_1, \tau_1) p( \phi | \alpha, \gamma)](https://s0.wp.com/latex.php?latex=p%28%5Cbeta_0%2C+%5Cbeta_1%2C+%5Cphi+%7C+%5Cvec+y%29+%5Cpropto+%5CBig+%5B%5Cprod_%7Bi%3D1%7D%5En+p%28y_i+%7C+%5Cbeta_0%2C+%5Cbeta_1%2C+%5Cphi+%29%5CBig%5D+p%28+%5Cbeta_0+%7C+%5Cmu_0%2C+%5Ctau_0+%29+p%28%5Cbeta_1+%7C+%5Cmu_1%2C+%5Ctau_1%29+p%28+%5Cphi+%7C+%5Calpha%2C+%5Cgamma%29+&bg=ffffff&fg=000000&s=0&c=20201002)
The term in the brackets is the joint distribution of the data, or likelihood. The other terms comprise the joint prior distribution of the parameters (since we implicitly assumed prior independence, the joint prior factors).
This is recognized as the familiar expression:

Part 0 of the accompanying R code generates data from this model for specified “true” parameters. We will later estimate a bayesian regression model with this data to check that we can recover these true parameters.
The Gibbs Sampler
To draw from this posterior distribution, we can use the Gibbs sampling algorithm. Gibbs sampling is an iterative algorithm that produces samples from the posterior distribution of each parameter of interest. It does so by sequentially drawing from the conditional posterior of the each parameter in the following way:

It can be shown that, after a suitable burn-in period, the remaining of the 1,000 draws are draws from the posterior distributions. These samples are not independent. The sequence of draws is a random walk in the posterior space and each step in the space depends on the previous position. Typically a thinning period will also be used (which is not done here). A thinning of 10 would mean that we keep every 10th draw. The idea being that each draw may be dependent on the previous draw, but not as dependent on the 10th previous draw.
Conditional Posterior Distributions
To use Gibbs, we need to identify the conditional posterior of each parameter.
It helps to start with the full unnormalized posterior:
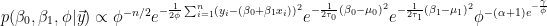
To find the conditional posterior of a parameter, we simply drop all terms from the joint posterior that do not include that parameter. For example, the constant term
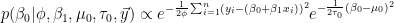
Similarly,
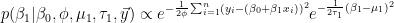
The conditional posterior can be recognized as another inverse gamma distribution, with some algebraic manipulation.
![\begin{aligned} p(\phi | \beta_0, \beta_1, \alpha, \gamma, \vec y) & \propto \phi^{-n/2} \phi^{-(\alpha + 1) e^{-\frac{\gamma}{\phi}}} e^{-\frac{1}{2\phi} \sum_{i=1}^{n}(y_i - (\beta_0 + \beta_1x_i) )^2} \\ & = \phi^{-(\alpha + \frac{n}{2} + 1)} exp{-\frac{1}{\phi} \Big[ \frac{1}{2\phi} \sum_{i=1}^{n}(y_i - (\beta_0 + \beta_1x_i) )^2 + \gamma \Big] } \\ & = IG(shape = \alpha + \frac{n}{2}, \ rate = \frac{1}{2\phi} \sum_{i=1}^{n}(y_i - (\beta_0 + \beta_1x_i) )^2 + \gamma ) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p%28%5Cphi+%7C+%5Cbeta_0%2C+%5Cbeta_1%2C+%5Calpha%2C+%5Cgamma%2C+%5Cvec+y%29+%26+%5Cpropto+%5Cphi%5E%7B-n%2F2%7D+%5Cphi%5E%7B-%28%5Calpha+%2B+1%29+e%5E%7B-%5Cfrac%7B%5Cgamma%7D%7B%5Cphi%7D%7D%7D+e%5E%7B-%5Cfrac%7B1%7D%7B2%5Cphi%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28y_i+-+%28%5Cbeta_0+%2B+%5Cbeta_1x_i%29+%29%5E2%7D+%5C%5C+%26+%3D+%5Cphi%5E%7B-%28%5Calpha+%2B+%5Cfrac%7Bn%7D%7B2%7D+%2B+1%29%7D+exp%7B-%5Cfrac%7B1%7D%7B%5Cphi%7D+%5CBig%5B+%5Cfrac%7B1%7D%7B2%5Cphi%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28y_i+-+%28%5Cbeta_0+%2B+%5Cbeta_1x_i%29+%29%5E2+%2B+%5Cgamma+%5CBig%5D+%7D+%5C%5C+%26+%3D+IG%28shape+%3D+%5Calpha+%2B+%5Cfrac%7Bn%7D%7B2%7D%2C+%5C+rate+%3D+%5Cfrac%7B1%7D%7B2%5Cphi%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28y_i+-+%28%5Cbeta_0+%2B+%5Cbeta_1x_i%29+%29%5E2+%2B+%5Cgamma+%29+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The conditional posteriors of 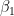
The Grid Method
Consider
Then the conditional posterior distribution evaluated at each grid point tells us the relatively likelihood of that draw.
We can then use the sample() function in R to draw from these grid of points, with sampling probabilities proportional to the density evaluation at the grid points.
This is implemented in functions rb0cond() and rb1cond() in part 1 of the accompanying R code.
It is common to encounter numerical issues when using the grid method. Since we are evaluating an unnormalized posterior on the grid, the results can get quite large or small. This may yield Inf and -Inf values in R.
In functions rb0cond() and rb1cond(), for example, I actually evaluate the log of the conditional posterior distributions derived. I then normalize by subtracting each evaluation from the maximum of all the evaluations before exponentiating back from the log scale. This tends to handle such numerical issues.
We don’t need to use the grid method to draw from the conditional posterior of 
Note that this grid method has some drawbacks.
First, it’s computationally expensive. It would be more computationally efficient to go through the algebra and hopefully get a known posterior distribution to draw from, as we did with
Second, the grid method requires specifying a region of grid points. What if the conditional posterior had significant density outside our specified grid interval of [-10,10]? In this case, we would not get an accurate sample from the conditional posterior. It’s important to keep this in mind and experiment with wide grid intervals. So, we need to be clever about handling numerical issues such as numbers approaching Inf and -Inf values in R.
Simulation Results
Now that we have a way to sample from each parameter’s conditional posterior, we can implement the Gibbs sampler. This is done in part 2 of the accompanying R code. It codes the same algorithm outlined above in R.
The results are good. The plot below shows the sequence of 1000 Gibbs samples (with burn-in draws removed and no thinning implemented). The red lines indicate the true parameter values under which we simulate the data. The fourth plot shows the joint posterior of the intercept and slope terms, with red lines indicating contours.

To sum things up, we first derived an expression for the joint distribution of the parameters. Then we outlined the Gibbs algorithm for drawing samples from this posterior. In the process, we recognized that the Gibbs method relies on sequential draws from the conditional posterior distribution of each parameter. For
I’ll try to follow up with an extension to a bayesian multivariate linear regression model in the near future.

Hello Arman,
Well done and thanks for the great job on “BAYESIAN SIMPLE LINEAR REGRESSION WITH GIBBS SAMPLING IN R”.
I have a little concern about the hyperparameters for \beta_1 used in the constant of proportionality expression. The hyperparameters you assumed for \beta_1 are \mu_1 and \tau_1 but you used \mu_0 and \tau_0 as the hyperparameters for the \beta_1. Please, explain.
Also, can you share your data or the R codes that generated the data and the R codes used in analysing the data with is for practice purposes?
Thanks
-Justice
Hi Justice,
Good eye! That was an error in the writing. I wanted \beta_0 and \beta_1 to have different hyperparameters.
In the conditional posterior of \beta_1, the correct hyperparamters are used.
The code for this post can be found in my Github repo:
https://github.com/stablemarkets/BayesSimpleLinearModel
The code is bayesmodel.R. Step 0 of the code generates the data. The rest of the code performs the analysis.
Best,
Arman
Hi Arman,
Thanks for this useful post.
I think you have a small mistake in the posterior distribution – your IG exponential part is written as a power of phi, when it should be factored IMO: https://en.wikipedia.org/wiki/Inverse-gamma_distribution#Probability_density_function
Many thanks,
Jon
Hi Jon. You’re absolutely right. I’ll update ASAP. Thanks for the catch!