Introduction The topic in this post is endogeneity, which can severely bias regression estimates. I will specifically simulate endogeneity caused by an omitted variable. In future posts in this series, I’ll simulate other specification issues such as heteroskedasticity, multicollinearity, and collider bias.
The Data-Generating Process
Consider the data-generating process (DGP) of some outcome variable :
For the simulation, I set parameter values for , , and and simulate positively correlated independent variables, and (N=500).
The simulation will estimate the two models below. The first model is correct in the sense that it includes all terms in the actual DGP. However, the second model omits a variable that is present in the DGP. Instead, the variable is obsorbed into the error term .
This second model will yield a biased estimator of . The variance will also be biased. This is because is endogenous, which is a fancy way of saying it is correlated with the error term, . Since and , then . To show this, I run the simulation below with 5,000 iterations. For each iteration, I construct the outcome variable, using the DGP. I then run a regression to estimate , first with model 1 and then with model 2.
sim=function(endog){
# assume normal error with constant variance to start
e=rnorm(n=ss,mean=0,sd=10)
y=a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){ fit=lm(y~x) }else{ fit=lm(y~x+z)}
return(fit$coefficients)
}
# run simulation - with and wihtout endogeneity
sim_results=t(replicate(trials,sim(endog=FALSE)))
sim_results_endog=t(replicate(trials,sim(endog=TRUE)))
Simulation Results This simulation yields two different sampling distributions for . Note that I have set the true value to . When is not omitted, the simulation yields the green sampling distribution, centered around the true value. The average value across all simulations is 0.4998. When is omitted, the simulation yields the red sampling distribution, centered around 0.5895. It’s biased upward from the true value of .5 by .0895. Moreover, the variance of the biased sampling distribution is much smaller than the true variance around . This compromises the ability to perform any meaningful inferences about the true parameter. Bias Analysis The bias in can be derived analytically. Consider that in model 1 (presented above), and are related by:
Substituting in equation 1 with equation 3 and re-ordering:
When omitting variable , it is actually equation 4 that is estimated. It can be seen that is biased by the quantity . In this case, since and are positively correlated by construction and their slope coefficients are positive, the bias will be positive. According to the parameters of the simulation, the “true” bias should be . Here is the distribution of the bias, it is centered around .0895, very close to the true bias value. The derivation above also lets us determine the direction of bias from knowing the correlation of and as well as the sign of (the true partial effect of on ). If both are the same sign, then the estimate of will be biased upward. If the signs differ, then the estimate of will be biased downward. Conclusion The case above was pretty general, but has particular applications. For example, if we believe that an individual’s income is a function of years of education and year of work experience, then omitting one variable will bias the slope estimate of the other.
I think to get a bias of about 0.09, “c” should be set to 0.1 instead of 0.01. In any case, the simulation with the parameters in the post yields a very small bias. Running your code, we get:
# generate two independent variables
x<-rnorm(n=ss,mean=1000,sd=50);
z<-d+h*x+rnorm(ss,0,10)
sim=function(endog){
# assume normal error with constant variance to start
e<-rnorm(n=ss,mean=0,sd=10)
y<-a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){
fit<-lm(y~x)
} else {
fit<-lm(y~x+z)
}
return(fit$coefficients)
}
sim_results=as.data.frame(t(replicate(trials,sim(endog=FALSE))))
sim_results_endog=as.data.frame(t(replicate(trials,sim(endog=TRUE))))
# run simulation – with and wihtout endogeneity
summary(sim_results)
## (Intercept) x z
## Min. :17.35 Min. :0.3522 Min. :-0.14377
## 1st Qu.:44.01 1st Qu.:0.4735 1st Qu.:-0.01851
## Median :49.81 Median :0.4997 Median : 0.01071
## Mean :49.95 Mean :0.4998 Mean : 0.01032
## 3rd Qu.:56.02 3rd Qu.:0.5261 3rd Qu.: 0.03908
## Max. :89.35 Max. :0.6445 Max. : 0.18044
summary(sim_results_endog)
## (Intercept) x
## Min. :17.98 Min. :0.4797
## 1st Qu.:43.99 1st Qu.:0.5031
## Median :50.04 Median :0.5092
## Mean :50.00 Mean :0.5092
## 3rd Qu.:56.12 3rd Qu.:0.5153
## Max. :79.44 Max. :0.5416
By contrast, setting it c = 0.1 yields:
# generate two independent variables
x<-rnorm(n=ss,mean=1000,sd=50);
z<-d+h*x+rnorm(ss,0,10)
sim=function(endog){
# assume normal error with constant variance to start
e<-rnorm(n=ss,mean=0,sd=10)
y<-a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){
fit<-lm(y~x)
} else {
fit<-lm(y~x+z)
}
return(fit$coefficients)
}
sim_results=as.data.frame(t(replicate(trials,sim(endog=FALSE))))
sim_results_endog=as.data.frame(t(replicate(trials,sim(endog=TRUE))))
# run simulation – with and wihtout endogeneity
summary(sim_results)
## (Intercept) x z
## Min. :17.35 Min. :0.3522 Min. :-0.05377
## 1st Qu.:44.01 1st Qu.:0.4735 1st Qu.: 0.07149
## Median :49.81 Median :0.4997 Median : 0.10071
## Mean :49.95 Mean :0.4998 Mean : 0.10032
## 3rd Qu.:56.02 3rd Qu.:0.5261 3rd Qu.: 0.12908
## Max. :89.35 Max. :0.6445 Max. : 0.27044
summary(sim_results_endog)
## (Intercept) x
## Min. :20.45 Min. :0.5603
## 1st Qu.:46.46 1st Qu.:0.5838
## Median :52.51 Median :0.5899
## Mean :52.48 Mean :0.5899
## 3rd Qu.:58.60 3rd Qu.:0.5959
## Max. :81.91 Max. :0.6223

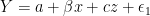
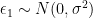

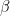



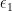

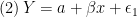




 Bias Analysis The bias in
Bias Analysis The bias in 




 The derivation above also lets us determine the direction of bias from knowing the correlation of
The derivation above also lets us determine the direction of bias from knowing the correlation of 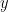

I think to get a bias of about 0.09, “c” should be set to 0.1 instead of 0.01. In any case, the simulation with the parameters in the post yields a very small bias. Running your code, we get:
# simulation parameters
set.seed(144);
ss=500; trials=5000;
a=50; b=.5; c=.01;
d=25; h=.9;
# generate two independent variables
x<-rnorm(n=ss,mean=1000,sd=50);
z<-d+h*x+rnorm(ss,0,10)
sim=function(endog){
# assume normal error with constant variance to start
e<-rnorm(n=ss,mean=0,sd=10)
y<-a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){
fit<-lm(y~x)
} else {
fit<-lm(y~x+z)
}
return(fit$coefficients)
}
sim_results=as.data.frame(t(replicate(trials,sim(endog=FALSE))))
sim_results_endog=as.data.frame(t(replicate(trials,sim(endog=TRUE))))
# run simulation – with and wihtout endogeneity
summary(sim_results)
## (Intercept) x z
## Min. :17.35 Min. :0.3522 Min. :-0.14377
## 1st Qu.:44.01 1st Qu.:0.4735 1st Qu.:-0.01851
## Median :49.81 Median :0.4997 Median : 0.01071
## Mean :49.95 Mean :0.4998 Mean : 0.01032
## 3rd Qu.:56.02 3rd Qu.:0.5261 3rd Qu.: 0.03908
## Max. :89.35 Max. :0.6445 Max. : 0.18044
summary(sim_results_endog)
## (Intercept) x
## Min. :17.98 Min. :0.4797
## 1st Qu.:43.99 1st Qu.:0.5031
## Median :50.04 Median :0.5092
## Mean :50.00 Mean :0.5092
## 3rd Qu.:56.12 3rd Qu.:0.5153
## Max. :79.44 Max. :0.5416
By contrast, setting it c = 0.1 yields:
# simulation parameters
set.seed(144);
ss=500; trials=5000;
a=50; b=.5; c=.1;
d=25; h=.9;
# generate two independent variables
x<-rnorm(n=ss,mean=1000,sd=50);
z<-d+h*x+rnorm(ss,0,10)
sim=function(endog){
# assume normal error with constant variance to start
e<-rnorm(n=ss,mean=0,sd=10)
y<-a+b*x+c*z+e
# Select data generation process
if(endog==TRUE){
fit<-lm(y~x)
} else {
fit<-lm(y~x+z)
}
return(fit$coefficients)
}
sim_results=as.data.frame(t(replicate(trials,sim(endog=FALSE))))
sim_results_endog=as.data.frame(t(replicate(trials,sim(endog=TRUE))))
# run simulation – with and wihtout endogeneity
summary(sim_results)
## (Intercept) x z
## Min. :17.35 Min. :0.3522 Min. :-0.05377
## 1st Qu.:44.01 1st Qu.:0.4735 1st Qu.: 0.07149
## Median :49.81 Median :0.4997 Median : 0.10071
## Mean :49.95 Mean :0.4998 Mean : 0.10032
## 3rd Qu.:56.02 3rd Qu.:0.5261 3rd Qu.: 0.12908
## Max. :89.35 Max. :0.6445 Max. : 0.27044
summary(sim_results_endog)
## (Intercept) x
## Min. :20.45 Min. :0.5603
## 1st Qu.:46.46 1st Qu.:0.5838
## Median :52.51 Median :0.5899
## Mean :52.48 Mean :0.5899
## 3rd Qu.:58.60 3rd Qu.:0.5959
## Max. :81.91 Max. :0.6223
You’re right! c should be .1. There must be some discrepancy between the code and output. Wow this was so long ago. Makes me feel old.